
API Báo cáo có an toàn không?
Tất cả dữ liệu được lưu trữ trong BigQuery đều được mã hóa khi lưu trữ và truyền đi. Điều này có nghĩa là khi dữ liệu được lưu trữ trên các máy chủ của Google và khi nó được truyền giữa các máy chủ đó và máy khách, dữ liệu được bảo vệ bằng mã hóa mạnh.
Ngoài ra, BigQuery còn có các biện pháp kiểm soát quyền truy cập tích hợp cho phép bạn hạn chế quyền truy cập vào dữ liệu của mình dựa trên vai trò và quyền của người dùng. Điều này có nghĩa là chúng tôi chỉ định chính xác ai có quyền truy cập dữ liệu của bạn và những hành động nào họ được phép thực hiện trên dữ liệu đó.
BigQuery cũng hỗ trợ xác thực và ủy quyền thông qua các cơ chế tiêu chuẩn như OAuth 2.0 và khóa API.
Cơ sở hạ tầng của Google được thiết kế để bảo vệ khỏi các mối đe dọa phổ biến như tấn công từ chối dịch vụ, vi phạm dữ liệu và truy cập trái phép. Điều này được thực hiện bằng nhiều biện pháp bảo mật khác nhau như tường lửa, hệ thống phát hiện xâm nhập và kiểm tra bảo mật thường xuyên. API BigQuery được thiết kế chú trọng đến bảo mật và sử dụng nhiều biện pháp để đảm bảo rằng dữ liệu của bạn luôn được bảo vệ.
Dữ liệu được cập nhật thường xuyên như thế nào?
Hằng ngày. Quá trình làm mới bắt đầu lúc nửa đêm UTC+0 với thời gian cập nhật tối đa là 12 giờ. Bản cập nhật bao gồm tất cả dữ liệu nhận được tính đến nửa đêm (UTC+0) của ngày hôm trước.
Dữ liệu quay trở lại bao xa?
Tất cả dữ liệu trước đây được phê duyệt cho một tổ chức nhất định sẽ có sẵn.
Nếu tôi là người dùng Truy cập Trực tiếp, làm cách nào để kết nối?
Khi đã ở trong GCP, thao tác sẽ liền mạch. Chỉ cần đăng nhập và cố gắng truy vấn các bảng có liên quan thông qua giao diện người dùng hoặc API.
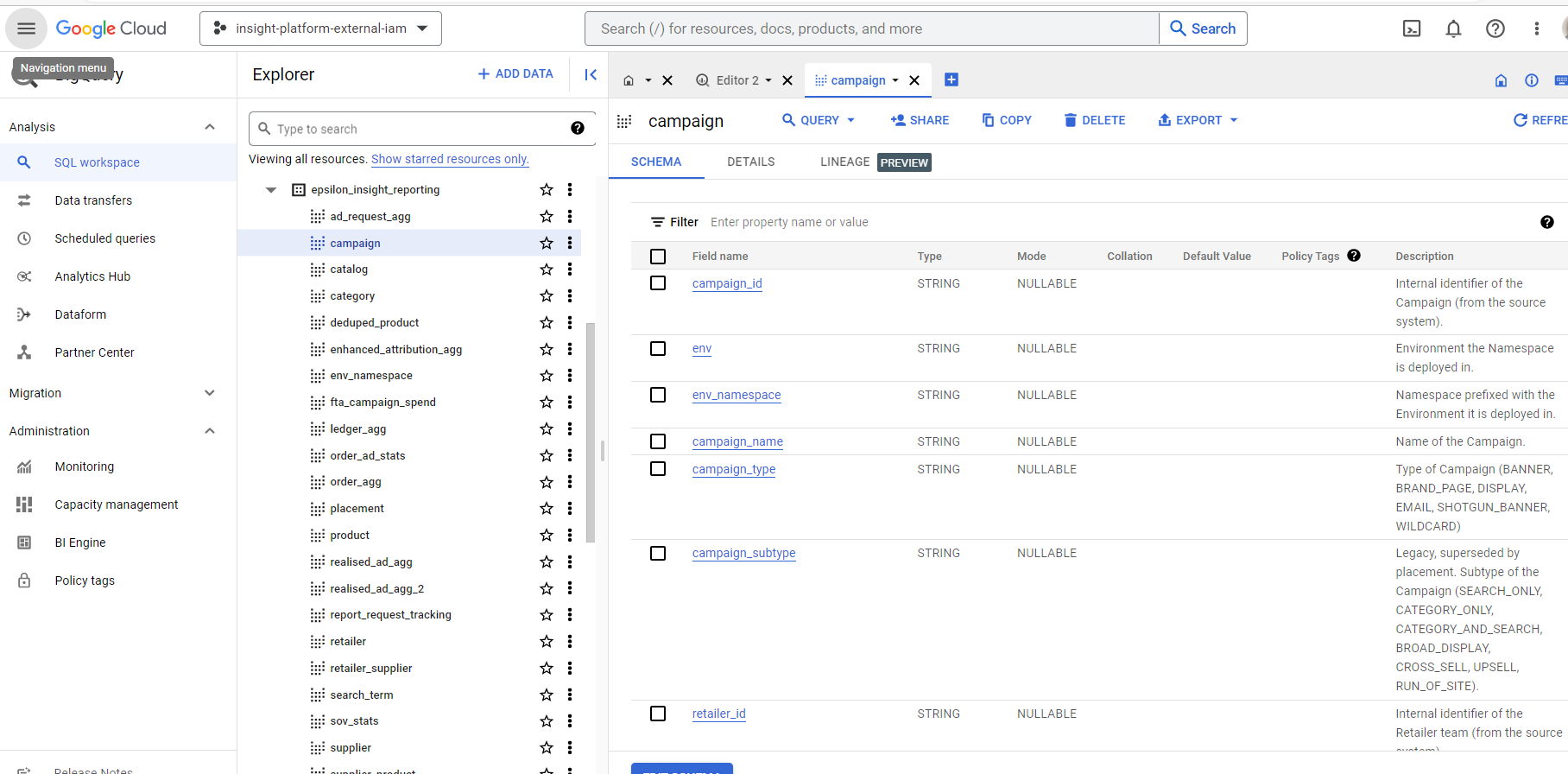
Tôi gặp lỗi "Người dùng không có quyền bigquery.jobs.create trong dự án" – tôi đã làm sai ở đâu?
Đối với các tài khoản bạn đã cung cấp cho chúng tôi, CitrusAd đã cấp quyền xem BigQuery cho các tập dữ liệu có liên quan. Việc này cho phép bạn đọc các bảng ở bên trong. Trong dự án, bạn phải thực hiện một số hành động thì mới truy vấn được các loại bảng từ xa này.
Hãy giả định như sau:
- Dự án của bạn = "client-project-123456"
- Người dùng của bạn = [email protected]
- Bộ dữ liệu CitrusAd: "insight-platform-external-iam.client_insight_reporting"
Bạn cần phải:
-
Cấp cho [email protected] quyền bigquery.jobs.create trong dự án client-project-123456 (không phải dự án CitrusAd). Bạn có thể thực hiện việc này bằng cách chỉ định vai trò Người dùng công việc BigQuery.
-
Khi thực hiện truy vấn, bạn phải chạy truy vấn trong dự án của mình (vì bạn chỉ có quyền đọc tập dữ liệu trong dự án CitrusAD, chứ không phải chạy các truy vấn trong đó). Bạn có thể làm việc này bằng cách sử dụng một lệnh cloud shell đơn giản (thực thi dưới dạng [email protected]):
bq query --use_legacy_sql=false --project_id client-project-123456 'SELECT * FROM insight-platform-external-iam.client_insight_reporting.campaign limit 10;'
Lưu ý rằng dự án khách hàng được đặt cho dự án của bạn, không phải insight-platform-external-iam.
Nếu sử dụng bất kỳ công cụ nào khác, bạn phải áp dụng bằng cách tương tự. Vui lòng tham khảo tài liệu của các công cụ để biết thêm thông tin, cũng như tài liệu trực tuyến của GCP để nằm được các bí quyết!
Vị trí của tôi không có dữ liệu CitrusAd, vậy làm thế nào để đưa được dữ liệu đó vào vị trí của tôi?
Có rất nhiều cách, nhưng dễ nhất là tạo các tập dữ liệu ở cùng vị trí với chúng tôi, sau đó thực hiện chuyển đổi, truy vấn, v.v. vào các bảng trong các tập dữ liệu đó, rồi sao chép vào vị trí bạn muốn.

Có nhiều cách để sao chép giữa các địa điểm bằng cách sử dụng giao diện người dùng, công cụ dòng lệnh BQ và chính API. Để biết thêm thông tin, vui lòng tham khảo các trang tài liệu Google Cloud sau:
Nếu tôi không phải là người dùng API GCP, làm cách nào để kết nối?
CitrusAd sẽ cung cấp cho bạn thông tin xác thực có liên quan trong JSON mà bạn có thể kết hợp vào cơ chế xác thực của mình.
Tôi có thể gỡ lỗi các truy vấn chỉ bằng API báo cáo (không phải giao diện người dùng BigQuery) không?
Có, API BigQuery sẽ trả về một mã cho biết liệu có sự cố hay không và thông báo lỗi cũng sẽ xuất hiện.
Tôi có thể ước tính chi phí cho một truy vấn không?
Có, API có cơ chế nhận ước tính byte về những gì truy vấn sẽ quét nếu được thực thi. Bạn có thể sử dụng ước tính đó nhân với tần suất bạn gọi truy vấn để hiểu mức độ bạn sẽ đạt đến hạn ngạch.
Thông tin thêm có thể được tìm thấy trong tài liệu GCP.
Truy vấn Dry run | BigQuery | Google Cloud
Nếu tôi vượt quá giới hạn hạn mức thì sao?
Vui lòng tham khảo thỏa thuận của bạn với CitrusAd để hiểu hạn mức của bạn là bao nhiêu. Nếu không được xác định cụ thể, hệ thống sẽ mặc định là 10TB lượt quét dữ liệu truy vấn mỗi tháng.
Thỏa thuận của bạn cũng có thể liên quan đến số lượng lệnh gọi API tối đa mỗi ngày. Nếu điều đó không được xác định cụ thể, mặc định có 100 lệnh gọi API mỗi ngày.
Trong trường hợp bạn vượt quá hạn mức (quét dữ liệu hoặc số lượng cuộc gọi), chúng tôi sẽ liên hệ để tìm hiểu trường hợp sử dụng của bạn. Chi phí quá mức có thể được áp dụng tùy theo thỏa thuận của bạn.
Trong trường hợp sử dụng sai mục đích nghiêm trọng ngoài các điều khoản trong thỏa thuận của bạn (hoặc giới hạn mặc định), chúng tôi có quyền đình chỉ quyền truy cập.
Ví dụ về việc sử dụng API báo cáo là gì?
Dưới đây là một số ví dụ sử dụng các phương pháp phổ biến.
Google SDK dành cho Python
Ví dụ này sẽ:
- Kết nối với BigQuery
- Chạy truy vấn
- Lưu kết quả vào một csv
import google.cloud.bigquery as bq
import pandas as pd
bq_client = bq.Client.from_service_account_json("<REPLACE>.json")
job_config = bq.QueryJobConfig(allow_large_results=True)
query_job = bq_client.query(
'SELECT count(1) FROM insight-platform-external-iam.<REPLACE>_insight_reporting.campaign
LIMIT 1000', job_config=job_config)
df = query_job.to_dataframe(create_bqstorage_client=False)
df.to_csv(r"C:\Users\<REPLACE>\<REPLACE>.csv", index=False)
print("Run Complete")
Các phương pháp khác có sẵn để ước tính số byte được quét, v.v. trước khi chạy truy vấn.
Vui lòng tham khảo tài liệu BigQuery
Nếu không có trong GCP, có thể tham chiếu tệp thông tin xác thực JSON thông qua biến môi trường.
API chung cho Python
import csv
import requests
from google.oauth2 import service_account
PROJECT_ID = "insight-platform-external-iam"
DATASET = "<YOUR DATASET HERE>"
END_POINT = f"https://bigquery.googleapis.com/bigquery/v2/projects/{PROJECT_ID}/queries"
QUERY = f"""
SELECT supplier_id, campaign_id, sum(ad_spend) as ad_spend, sum(clicks) as clicks
FROM `{PROJECT_ID}.{DATASET}.realised_ad_agg`
WHERE ingressed_at BETWEEN '2022-09-01' and '2022-12-31'
group by 1,2
"""
def get_token():
# With service account
credentials = service_account.Credentials.from_service_account_file('./secrets/service-account.json')
scoped_credentials = credentials.with_scopes(['https://www.googleapis.com/auth/cloud-platform'])
# Do token request
def req( method, url, headers, body, **kwargs):
resp = requests.post(url, headers=headers, data=body)
return type('obj', (object,), {'data' : resp.text, 'status': 200})
scoped_credentials.refresh(req)
return scoped_credentials.token
def run_job(token):
resp = requests.post(
END_POINT,
json={
"query": QUERY,
"useLegacySql": False
},
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
}
)
return resp.json()['jobReference']['jobId']
def get_query_results(job_id, token):
status_endpoint = f'{END_POINT}/{job_id}?location=australia-southeast1'
completed = False
while not completed:
response = requests.get(status_endpoint, headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
})
completed = response.json()['jobComplete']
data = response.json()
rows = data['rows']
columns = [c['name'] for c in data['schema']['fields']]
return rows, columns
def extract():
token = get_token()
job_id = run_job(token)
rows, columns = get_query_results(job_id, token)
with open('results.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(columns)
for row in rows:
writer.writerow([i['v'] for i in row['f']])
extract()
Điều gì sẽ xảy ra nếu tôi ở trong AWS, v.v. chứ không phải Google Cloud, tôi vẫn có thể xác thực và sử dụng API?
Có, chức năng sẽ hoạt động. Chúng tôi sẽ cung cấp thông tin xác thực tài khoản dịch vụ và bạn có thể tham chiếu chúng trong đơn đăng ký của mình. Đây là một ví dụ.
# TODO(developer): Set key_path to the path to the service account key
# file.
# key_path = "path/to/service_account.json"
credentials = service_account.Credentials.from_service_account_file(
key_path, scopes=["https://www.googleapis.com/auth/cloud-platform"],
)
token = credentials.token
# use the token to do the API calls
# ...
# headers: Bearer ${token}
# ...
Làm cách nào tôi có thể xác định vị trí của từng tập dữ liệu được chia sẻ với tôi?
Lệnh gọi API này sẽ cho bạn biết vị trí của từng tập dữ liệu.
GET https://bigquery.googleapis.com/bigquery/v2/projects/insight-platform-external-iam/datasets
{
"kind": "bigquery#datasetList",
"etag": "RLU1Ww9C5FdhlcIuRHjW0A==",
"datasets": [
{
"kind": "bigquery#dataset",
"id": "insight-platform-external-iam:acme_insight_reporting",
"datasetReference": {
"datasetId": "acme_insight_reporting",
"projectId": "insight-platform-external-iam"
},
"location": "australia-southeast1"
},
{
"kind": "bigquery#dataset",
"id": "insight-platform-external-iam:acme_acme_analytics",
"datasetReference": {
"datasetId": "acme_acme_analytics",
"projectId": "insight-platform-external-iam"
},
"location": "us-central1"
}
]
}
Lời khuyên thực hành tốt nhất?
Nói chung, nếu bạn có ý định sử dụng nhiều dữ liệu, đặc biệt nếu bạn có quyền truy cập dữ liệu chưa tổng hợp (yêu cầu/quảng cáo đã thực hiện/đơn đặt hàng/phân bổ nâng cao, v.v.), thì tốt nhất bạn nên sao chép (giai đoạn) các bảng vào kho dữ liệu của riêng bạn, SAU ĐÓ triển khai các truy vấn cho logic nghiệp vụ cần thiết của bạn trên các bản sao đó.
Người dùng hiểu biết hơn có thể chỉ cần chọn truy vấn trực tiếp các bảng để có kết quả cụ thể.
Điều quan trọng là phải duy trì dưới mức hạn mức cho phép để đảm bảo hoạt động trơn tru.
Cũng lưu ý rằng mỗi truy vấn có thể tải xuống tối đa 1 GB, nếu không sẽ nhận được thông báo lỗi. Trong trường hợp cần tải xuống lượng rất lớn, thay vào đó hãy chạy một số truy vấn nhỏ hơn (ví dụ: tập hợp con dữ liệu mỗi ngày hoặc nhà cung cấp, v.v.)
Nếu tôi cần trợ giúp để tạo các câu lệnh SQL thích hợp thì sao?
Hãy gửi một yêu cầu chỉ định truy vấn mà bạn đã thử và chúng tôi có thể giúp xem xét yêu cầu đó - chúng tôi sẽ liên hệ lại với bạn nếu có bất kỳ nhận xét nào mà chúng tôi có thể có.
Bạn có lời khuyên nào khi sử dụng gói Pandas không?
Pandas là một trong những công cụ phân tích phổ biến nhất. Để làm cho công cụ hoạt động, cần phải cài đặt các phần phụ thuộc pandas-gbq và pydata-google-auth.
Đoạn mã bên dưới là ví dụ hoạt động về cách đọc dữ liệu từ bảng BigQuery.
import pandas as pd
from google.oauth2 import service_account
credentials = service_account.Credentials.from_service_account_file('path/to/the/credential/file')
query = 'select * from project.dataset.table'
dat = pd.read_gbq(
query,
project_id='project_id',
credentials=credentials
)
Thông tin thêm về chức năng Pandas có thể được tìm thấy ở đây.
Bạn có lời khuyên nào khi sử dụng gói PySpark không?
Giả sử bạn có môi trường PySpark đang hoạt động, bạn cần cung cấp tệp jar chính xác cho trình kết nối BigQuery phù hợp với phiên bản PySpark của bạn. Ví dụ: PySpark 3.2.* yêu cầu spark-3.2-bigquery-0.30.0.jar. Bạn có thể tìm thấy danh sách các tệp jar cũng như các đoạn mã và tham số thực tế tại đây.
Đoạn mã bên dưới cung cấp ví dụ về cách chạy truy vấn.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('BigNumeric').config('spark.jars', 'spark-3.2-bigquery-0.30.0.jar').getOrCreate()
spark.conf.set('credentialsFile', 'path/to/the/credential/file')
spark.conf.set('viewsEnabled', 'true')
spark.conf.set('materializationProject', 'yourMaterializationProject')
spark.conf.set('materializationDataset', 'yourMaterializationDataset')
query = 'select * from project.dataset.table'
df = spark.read.format('bigquery').option('query', query).load()
df.show()
QUAN TRỌNG: Thông số viewEnabled phải đúng.
Dữ liệu trong chế độ xem được cụ thể hóa trong các bảng tạm thời trước khi được PySpark đọc khi cần có quyền bigquery.tables.create. Do đó, bạn cần cung cấp Dự án thực hiện và Bộ dữ liệu thực hiện nơi người dùng có quyền truy cập ghi.
Tôi gặp lỗi khi yêu cầu bộ lọc trong truy vấn?
Đối với một bảng được phân vùng, bộ lọc là bắt buộc, nếu không có bộ lọc này thì thông báo lỗi như bên dưới sẽ được đưa ra:
Không thể truy vấn bảng ‘dataset_id.table_id' không có bộ lọc trên (các) cột ‘partitioned_column' có thể được sử dụng để loại bỏ phân vùng
Để khắc phục lỗi, chỉ cần thêm bộ lọc hợp lý bao gồm phạm vi mục tiêu, ví dụ:
-- this query returns all records available since yesterday
select
*
from
dataset_id.table_id
where
ingressed_at >= date_sub(current_date, interval 1 day)
Để tìm ra cột nào được phân vùng trong bảng (như ingressed_at trong ví dụ trên), hãy tham khảo mô tả của bảng đã cho.
Làm cách nào tôi có thể yêu cầu quyền truy cập?
Quá trình
Một vé phải được nêu ra và các tiêu chí đủ điều kiện được đồng ý bằng văn bản.
Chúng tôi sẽ làm việc với Ứng viên tiềm năng để xác định mức độ truy cập và cài đặt bảo mật cần thiết cũng như xác định hạn mức và chi phí có thể áp dụng.
Tiêu chí đủ điều kiện
Ứng viên phải tuân thủ các Tiêu chí sau để được coi là đủ điều kiện truy cập API Báo cáo: -
Chung
- Ứng viên chỉ có thể yêu cầu quyền truy cập vào dữ liệu cho các nhóm và không gian tên CitrusAd mà họ đã là thành viên hoặc có quyền truy cập chung. Ứng viên phải nêu rõ họ đang đăng ký trường hợp nào sau đây (và cung cấp bằng chứng về quyền truy cập hiện có):
- Cấp độ môi trường (toàn bộ quá trình triển khai nền tảng CitrusAd được dành riêng cho Ứng viên).
- Cấp độ không gian tên (Ứng viên có quyền xem tất cả các nhóm, cả nhà bán lẻ và nhà cung cấp, trong Không gian tên riêng lẻ hoặc danh sách Không gian tên).
- Id nhóm nhà bán lẻ cụ thể hoặc cấp độ nhóm.
- Id nhóm nhà cung cấp cụ thể hoặc cấp độ nhóm.
- Ngoài ra, Người hợp nhất có thể truy cập id Nhóm nhà cung cấp cụ thể hoặc cấp độ nhóm CỘNG VỚI đầy đủ Danh mục sản phẩm của Nhà bán lẻ khi được Nhà bán lẻ đồng ý trong từng trường hợp.
- Dữ liệu thực tế giao dịch chỉ có thể được cung cấp cho Ứng viên đủ điều kiện cho Tiêu chí chung 1a hoặc 1b.
- Các ứng viên không đủ điều kiện nhận Dữ liệu thực tế giao dịch sẽ chỉ được cung cấp quyền truy cập vào Dữ liệu thực tế tổng hợp trước. Dữ liệu sẽ được tổng hợp thành các bản tóm tắt hàng ngày (trong đó UTC+0 là múi giờ tổng hợp).
- Các ứng viên chỉ đủ điều kiện cho Tiêu chí chung 1d sẽ không thể nhận dữ liệu Yêu cầu quảng cáo (trái ngược với dữ liệu Quảng cáo đã thực hiện sẽ được cung cấp). Dữ liệu sản phẩm sẽ được cung cấp cho các Sản phẩm cụ thể đang được Nhà cung cấp quảng cáo trong Quảng cáo đã thực hiện NGOẠI TRỪ các Người hợp nhất có thể nhận Danh mục sản phẩm của nhà bán lẻ khi được Nhà bán lẻ đồng ý theo từng trường hợp.
- Dữ liệu kích thước chỉ được đảm bảo bao gồm các phiên bản hiện tại của các bản ghi được đề cập. Dự kiến, việc theo dõi các thay đổi lịch sử sẽ được Ứng viên thực hiện khi họ yêu cầu.
- Dữ liệu được cập nhật hàng ngày và sẽ được cập nhật không muộn hơn 12:00 UTC+0 cho dữ liệu lên đến và bao gồm cả ngày UTC+0 đã hoàn thành trước đó.
- Điều này được hiểu rằng về bản chất quyền truy cập chỉ được đọc. API không được sử dụng để tạo đối tượng trong kho dữ liệu của chúng tôi cho bất kỳ mục đích nào.
- Mọi việc kết hợp với các nguồn dữ liệu khác đều phải được thực hiện trong môi trường riêng của Ứng viên.
- Ứng viên phải có sẵn SDK (hoặc tương đương) để truy cập API Google BigQuery.
- Ứng viên có kiến thức tốt về SQL.
- Ứng viên phải quen thuộc với các khái niệm CitrusAd và nếu không, sẽ sắp xếp đào tạo sản phẩm tiêu chuẩn được cung cấp thông qua Người quản lý hỗ trợ khách hàng hoặc Người quản lý tài khoản kỹ thuật của họ.
- Dựa trên các tài liệu được cung cấp, Ứng viên dự kiến sẽ phát triển các giải pháp của riêng mình. Nếu một vấn đề được tìm thấy với SQL không hoạt động như mong đợi theo tài liệu, cần phải đưa ra yêu cầu hỗ trợ thông qua các kênh hỗ trợ thông thường. Các thông tin sau đây phải được cung cấp.
- Tài khoản mà kết nối đang được thực hiện.
- SQL chính xác đang được gọi.
- Mô tả chi tiết về những thông báo lỗi xuất hiện.
- Nếu Ứng viên là Nhà bán lẻ, thì số lần Hiển thị/Số lần nhấp/Đơn đặt hàng phải được cung cấp cho nền tảng CitrusAd để có thể thiết lập một bức tranh hoàn chỉnh về Vòng đời của Quảng cáo.
- Đôi khi, CitrusAd có quyền thay đổi lược đồ. Những thay đổi này thường liên quan đến việc bổ sung các cột mới vào các bảng và dạng xem hiện có và sẽ tương thích ngược. Ứng viên phải cấu trúc SQL của họ để đặt tên cho các cột thay vì sử dụng ký tự đại diện, v.v. Trong trường hợp thay đổi liên quan đến việc ngừng sử dụng cột hoặc bảng, CitrusAd sẽ đưa ra thông báo ít nhất 12 tuần về thay đổi trước khi thực hiện. Thông báo sẽ xuất hiện thông qua thông tin phát hành tiêu chuẩn được gửi tới người dùng nền tảng.
Ứng viên không bắt buộc phải là người dùng Google Cloud Platform (GCP) hiện tại; tuy nhiên, có tồn tại các Tiêu chí khác tùy thuộc vào việc Ứng viên có phải là người dùng GCP hay không phải người dùng GCP.
Ứng viên không phải người dùng GCP
Trừ khi có thỏa thuận khác, CitrusAd sẽ cung cấp thông tin đăng nhập cho một tài khoản dịch vụ duy nhất trong môi trường của chúng tôi cho Ứng viên.
Trừ khi có thỏa thuận khác, các điều kiện mặc định sau đây sẽ được áp dụng:
- Tối đa 100 lệnh gọi API mỗi ngày.
- Không quá 10TB quét dữ liệu mỗi tháng (lưu ý, API có cách ước tính kích thước quét truy vấn trước khi thực thi, hãy tham khảo tài liệu của Google Truy vấn Dry run | BigQuery | Google Cloud).
- Nếu vượt quá Tiêu chí 1 và/hoặc 2 dành cho ứng viên không phải người dùng GCP, CitrusAd có quyền tạm dừng quyền truy cập theo quyết định riêng của chúng tôi.
- Không có lệnh gọi API riêng lẻ nào có thể tải xuống hơn 1GB dữ liệu cùng một lúc.
Làm cách nào để giải mã tệp tài khoản dịch vụ?
Thông tin đăng nhập tài khoản dịch vụ sẽ được cung cấp cho bạn theo định dạng mã hóa base64 để bảo mật trong quá trình truyền tin. Bạn phải giải mã trước khi sử dụng. Sau đây là ví dụ cách giải mã tệp:
Sử dụng bash:
# Replace encoded-credentials.txt with the file containing your base64 encoded credentials
base64 -d encoded-credentials.txt > service-account.json
Sử dụng Python:
import base64
# Replace encoded_credentials with your base64 encoded string
with open('encoded-credentials.txt', 'r') as f:
encoded_credentials = f.read()
decoded_credentials = base64.b64decode(encoded_credentials)
with open('service-account.json', 'wb') as f:
f.write(decoded_credentials)
Sau khi giải mã, bạn sẽ có một service-account.json tệp mà bạn có thể sử dụng với các thư viện ứng dụng BigQuery như đã trình bày trong các ví dụ trước đó.
Ứng viên là người dùng GCP
Trừ khi có thỏa thuận khác, Ứng viên sẽ cung cấp chi tiết CitrusAd của không quá 5 tài khoản GCP để chúng tôi có thể chỉ định quyền truy cập cần thiết.
Lưu ý rằng tài khoản phải có vai trò Người dùng công việc BigQuery (roles/bigquery.jobUser) được chỉ định.
Các hạn chế sau đây được áp dụng:
- Tối đa 100 lệnh gọi API mỗi ngày.
- Nếu vượt quá Tiêu chí 1 của Ứng viên người dùng GCP, CitrusAd có quyền tạm dừng quyền truy cập theo quyết định riêng của chúng tôi.
- Không có lệnh gọi API riêng lẻ nào có thể tải xuống hơn 1GB dữ liệu.
Bảng thuật ngữ
Môi trường
Tên của môi trường vật lý nền tảng CitrusAd được triển khai. Mỗi máy chủ lưu trữ một hoặc nhiều không gian tên.
Không gian tên
Cách tạo nhóm hợp lý bao gồm tất cả các thực thể là một phần của việc triển khai giải pháp CitrusAd. Không gian tên bao gồm các nhóm và tất cả các đối tượng thuộc sở hữu của các nhóm. Thông thường, một không gian tên có thể bao gồm một nhà bán lẻ (nhóm) và nhiều nhà cung cấp (nhiều nhóm) cùng với người dùng cho mỗi nhóm và cấu hình có liên quan khác (danh mục riêng của nhà bán lẻ, nhà cung cấp định cấu hình chiến dịch, v.v.). Các nhóm (và những nội dung họ sở hữu) chỉ thuộc về một không gian tên duy nhất (không nhóm nào có thể tồn tại trên nhiều không gian tên).
Người dùng
Mã nhận dạng duy nhất của người dùng trong hệ thống CitrusAd. Một email có thể có nhiều userId. Mỗi userId là duy nhất cho mỗi không gian tên. Mỗi người dùng sẽ có tên, họ, email và id. Người dùng có thể là thành viên và truy cập vào nhiều nhóm trong nền tảng CitrusAd.
Nhóm
Một nhóm trong hệ thống CitrusAd. Có thể là nhà cung cấp (nhà quảng cáo) hoặc nhà bán lẻ. Các nhóm nhà cung cấp thường sẽ tạo chiến dịch, nhà bán lẻ đánh giá chiến dịch và thực hiện các chức năng quản trị. Một người dùng trong hệ thống CitrusAd có thể là thành viên của nhiều nhóm hoặc chỉ một nhóm. Một nhóm thường sẽ có người dùng, chiến dịch và ví được liên kết với nhóm.
Nhà cung cấp
Một nhóm nhà cung cấp trong hệ thống CitrusAd. Một nhà cung cấp thường có thể là một công ty mẹ của thương hiệu hoặc một loạt các nhóm cho mỗi thương hiệu riêng lẻ. Các nhà cung cấp thường duy trì các chiến dịch, quản lý số dư ví, v.v.
Nhà bán lẻ
Một nhóm nhà bán lẻ trong hệ thống CitrusAd. Hầu hết các không gian tên sẽ chỉ có một nhóm nhà bán lẻ. Các nhà bán lẻ thường duy trì danh mục sản phẩm, đánh giá các chiến dịch, v.v.
Chiến dịch
Một chiến dịch duy nhất được định cấu hình với chiến lược nhắm mục tiêu và vị trí cho một lựa chọn sản phẩm cụ thể. Ví dụ: chiến dịch trong hệ thống CitrusAd có thể đang quảng bá sản phẩm A và B nhắm mục tiêu các cụm từ tìm kiếm "chocolate" và "chocolates" với giá thầu tối đa là 0,60 USD. Một nhóm thường có nhiều chiến dịch.
Danh mục
Danh mục sản phẩm của nhà bán lẻ duy nhất trong hệ thống CitrusAd. Thông thường, nhà bán lẻ chỉ đồng bộ hóa một danh mục sản phẩm với CitrusAd trong một không gian tên duy nhất. Danh mục sẽ có danh sách tất cả các sản phẩm trong danh mục của nhà bán lẻ, tên, nhãn hiệu, danh mục và các thuộc tính có liên quan khác được nhập vào hệ thống CitrusAd.
Sản phẩm
Một sản phẩm duy nhất trong hệ thống CitrusAd. Sản phẩm sẽ có một mã sản phẩm duy nhất được đồng bộ trong danh mục sản phẩm. Một sản phẩm có thể có các thuộc tính như danh mục, phân loại, thương hiệu, v.v.
Ví
Ví trong hệ thống CitrusAd lưu trữ tiền của nhà quảng cáo nhằm mục đích thực hiện thanh toán (ví dụ: thanh toán cho các quảng cáo đã thực hiện). Mỗi ví có một mã tiền tệ duy nhất và chỉ có thể chi tiêu cho các danh mục có cùng mã tiền tệ đó. Ví được sở hữu bởi một nhóm. Nhóm có thể sở hữu một hoặc nhiều ví. Ví có thể được lưu trữ. Lưu trữ ví sẽ chỉ hiển thị/ẩn ví trong nền tảng, ví được lưu trữ vẫn có thể chi tiêu tín dụng.
Sổ cái
Sổ cái các sự kiện dẫn đến giao dịch trong hệ thống CitrusAd. Đây là sự kiện quảng cáo phổ biến nhất, chẳng hạn như số lần hiển thị hoặc số lần nhấp vào sản phẩm được tài trợ hoặc quảng cáo biểu ngữ (Ghi nợ). Đây cũng có thể là các khoản nạp thêm và điều chỉnh số dư của nhà cung cấp (Ghi có). Mỗi sự kiện sẽ có một 'lý do' ví dụ như Sản phẩm được tài trợ, Quảng cáo biểu ngữ, Nạp tiền.
Yêu cầu
Một yêu cầu được gửi đến hệ thống CitrusAd về quảng cáo. Trong yêu cầu, nhà bán lẻ chỉ định vị trí cũng như ngữ cảnh, chẳng hạn như sessionId của khách hàng hoặc các bộ lọc có liên quan đến yêu cầu. Tùy thuộc vào yêu cầu, CitrusAd sẽ gửi lại quảng cáo của Loại quảng cáo có liên quan (ví dụ: Danh mục hoặc Cụm từ tìm kiếm) cho nhà bán lẻ để hiển thị cho khách hàng.
Quảng cáo (Đã thực hiện)
Quảng cáo là sự kiện quảng cáo đơn lẻ được gửi lại cho nhà bán lẻ để phân phối cho khách hàng của họ. Nó trở thành quảng cáo đã thực hiện khi nhà bán lẻ trả lại xác nhận rằng quảng cáo đã được hiển thị ít nhất (xác nhận rõ ràng rằng quảng cáo đã thực sự được sử dụng, tức là đã thực hiện) . Trong hệ thống CitrusAd, mỗi quảng cáo sẽ có một id realisedad duy nhất là một tham chiếu cho sự kiện đơn lẻ duy nhất đó.
Danh mục
Danh mục là một trang trên trang web của nhà bán lẻ như một phần trong hệ thống phân loại trang web của họ, ví dụ như "Bánh ngọt" hoặc "Sữa". Nhà bán lẻ thường yêu cầu quảng cáo trên một trang danh mục và xác định thuộc tính có liên quan này trong yêu cầu của họ cho CitrusAd. Nếu CitrusAd có chiến dịch đang hoạt động và hợp lệ cho Danh mục, quảng cáo sẽ được trả lại.
searchTerm
Cụm từ tìm kiếm được khách hàng nhập vào trang web của nhà bán lẻ. Cụm từ tìm kiếm này sau đó được gửi đến CitrusAd để yêu cầu quảng cáo có liên quan. Nếu CitrusAd có chiến dịch đang hoạt động và hợp lệ cho cụm từ tìm kiếm, quảng cáo sẽ được trả lại.
Đơn hàng
Đơn hàng duy nhất trong hệ thống của nhà bán lẻ được đồng bộ hóa với CitrusAd. Một đơn hàng có thể có nhiều orderItems bên trong đơn hàng (giống như giỏ hàng của khách hàng có thể chứa nhiều mặt hàng). Sau khi đơn hàng của khách hàng hoàn tất, chúng sẽ được gửi đến CitrusAd để hỗ trợ phân bổ của CitrusAd. Sau đó, lợi nhuận trên chi tiêu quảng cáo (ROAS) và các KPI quan trọng khác có thể được cung cấp cho các nhà bán lẻ và nhà quảng cáo.
Phân bổ
Phân bổ là một quy trình được vận hành trong hệ thống CitrusAd chỉ định quảng cáo được cấp phát cho khách hàng theo đơn hàng đã gửi. Một hành trình khách hàng điển hình sẽ là họ nhìn thấy quảng cáo (hiển thị), nhấp vào quảng cáo (nhấp chuột), thêm quảng cáo vào giỏ hàng của họ và mua mặt hàng đó (chuyển đổi). Đơn hàng được 'phân bổ' cho quảng cáo duy nhất khách hàng đã nhấp vào. Để đơn hàng được phân bổ trong hệ thống CitrusAd, quảng cáo cần được tương tác (được nhìn thấy hoặc nhấp vào tùy thuộc vào tích hợp) và sau đó khách hàng đã mua một mặt hàng có liên quan đến quảng cáo. CitrusAd thường sử dụng 'sessionId' để phân bổ đơn hàng cho quảng cáo, trong đó nhà bán lẻ chỉ định 'sessionId' trong tất cả các điểm tiếp xúc có liên quan của hành trình quảng cáo. Đây là cách CitrusAd có thể xác định rằng một quảng cáo duy nhất, được cấp phát cho một khách hàng duy nhất, đã mang đến đơn hàng cụ thể.
Ngày
Tất cả dữ liệu được truyền vào múi giờ UTC+0 nếu được tổng hợp.
Giới hạn
Việc triển khai nền tảng CitrusAd thường liên quan đến việc nhà bán lẻ yêu cầu nhiều quảng cáo hơn mức thực tế sẽ được hiển thị (thực hiện). Từ góc độ phân tích, việc này có thể đưa ra lượt hiển thị không chính xác về cách các chỉ số nhất định đang thực sự hoạt động.
Ví dụ: nếu một yêu cầu được đưa ra cho 20 quảng cáo (AdType=Product) và nền tảng đã phân phối 2 quảng cáo trong phản hồi, thì điều đó thể hiện 'tỷ lệ lấp đầy' là 10% cho yêu cầu (2 trên 20). Tuy nhiên, nếu hiểu rằng trong thực tế chỉ có 4 quảng cáo có khả năng từng được sử dụng (thực hiện), thì tốt hơn nên hiểu là 50% được lấp đầy (2 trên 4).
Do đó khái niệm về giới hạn trong báo cáo được đưa ra.
Giới hạn được đặt cho mỗi nhà bán lẻ, với một giới hạn có sẵn cho quảng cáo sản phẩm và giới hạn khác cho quảng cáo biểu ngữ (vì yêu cầu quảng cáo sản phẩm thường sẽ yêu cầu và sử dụng nhiều quảng cáo hơn nhiều so với quảng cáo biểu ngữ).
Quay trở lại ví dụ, nếu giới hạn sản phẩm = 4 đối với nhà bán lẻ, thì chỉ số yêu cầu sẽ báo cáo như sau:-
NumAdRequests = 1
NumAdsRequested = 20
CappedNumAdsRequested = 4
NumAdsServed = 2
CappedNumAdsServed = 2
Lưu ý, trong trường hợp có 5 quảng cáo được phân phối (tức là quảng cáo được phân phối vượt quá giới hạn), 2 chỉ số cuối cùng sẽ báo cáo như sau:-
NumAdsServed = 5
CappedNumAdsServed = 4 (được giảm bớt về số lượng giới hạn)
Không bắt buộc phải đưa ra các giới hạn. Trong trường hợp các giới hạn không được chỉ định, sau đó kết quả được giới hạn và không được giới hạn sẽ giống nhau.
Phân bổ nâng cao
Nền tảng CitrusAd thực hiện phân bổ như được nêu trong phần Phân bổ (xem ở trên).
Hệ thống con báo cáo cũng có thể phát hiện và gắn cờ các trường hợp phân bổ khác tùy thuộc vào nhà bán lẻ (phân bổ nâng cao).
Các kịch bản là:
- Chế độ xem lượt hiển thị thông qua phân bổ
- Đơn hàng được phân bổ cho Quảng cáo đã được xem cho cùng một Sản phẩm trong cùng một id phiên (nghĩa là một lượt hiển thị chứ không phải một lượt nhấp chuột).
- Phân bổ lượt nhấp chuột lan tỏa
- Đơn đặt hàng được phân bổ cho một quảng cáo đã được nhấp vào cho một Sản phẩm thuộc cùng cấp độ lan tỏa trong cùng một id phiên. Cấp độ lan tỏa phổ biến nhất là Thương hiệu (nghĩa là Sản phẩm của Quảng cáo và Sản phẩm của Đơn hàng khác nhau, nhưng thuộc cùng một Thương hiệu). Mỗi phương pháp triển khai lại tương ứng với một loại hình lan tỏa khác nhau. Ví dụ: hiệu ứng lan tỏa có thể cụ thể hơn và cần có Quảng cáo và Đơn hàng dành cho Sản phẩm có Danh mục chung bên cạnh Thương hiệu chung. Phân loại nhà bán lẻ được đặt cho mỗi Sản phẩm trong Danh mục được sử dụng để xác định mức độ chi tiết bổ sung này trong Hiệu ứng lan tỏa.
Phiên bản: 9c46030